I. 架构核心与基本结构
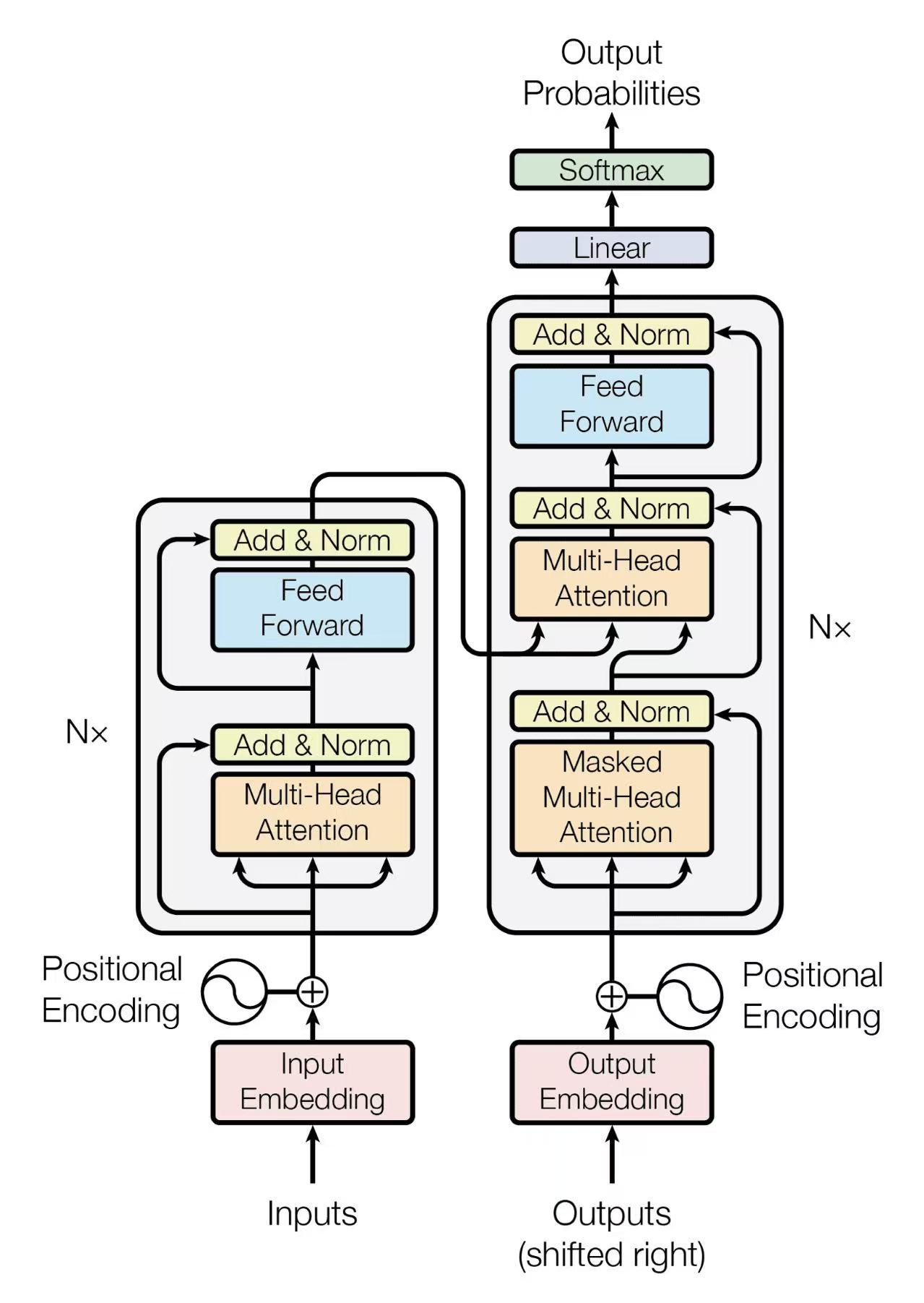
Transformer 完整架构图
本节探讨 GPT 所基于的 Transformer 架构的核心概念。Transformer 是专为处理序列数据(如文本)而设计的基础神经网络架构。我们将了解为什么 GPT 选择了一种"仅解码器"的特殊结构。
编码器 (Encoder) - 未采用
负责理解**输入**序列的含义,生成上下文表示。在传统的翻译任务中至关重要,但 GPT 将其功能并入了解码器。
解码器 (Decoder) - GPT 核心
负责根据输入(或已生成内容)生成**输出**序列。GPT 采用了“仅解码器”架构,专注于利用上下文生成连贯的文本。
核心特点
- 通过自注意力机制实现全局上下文理解。
- 支持大规模并行计算,这是其能够扩展到巨大规模的关键。
- 实现强大的、连贯的语言生成能力。
II. 基础输入处理
在模型能“理解”文本之前,我们必须将词语转换为它能处理的数字格式。这包括两个关键步骤:词向量化和位置编码。
1. 词向量 (Word Embedding)
将离散的词语转换为连续的、包含语义和语法信息的数值向量(就像“词语的身份证”)。每个词都被映射到一个固定的高维向量空间。
2. 位置编码 (Positional Encoding)
自注意力机制本身不关心词序(“猫追狗”和“狗追猫”可能看起来一样)。我们必须**注入**位置信息。GPT 使用三角函数(正弦和余弦)来为每个位置生成一个独特的向量。
PE(pos, 2i) = sin(pos / 10000^(2i / d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i / d_model))
这个向量随后与词向量相加:
输入向量 = 词向量 + 位置编码向量
位置编码可视化
点击按钮来生成一个 10 个词、128 维的位置编码矩阵的可视化(热力图)。每一行代表一个词的位置,每一列代表一个维度。注意看每一行都是独一无二的。
III. 核心机制:自注意力
这是 Transformer 的“大脑”。自注意力允许模型在处理一个词时,权衡句子中所有其他词的重要性。这是通过 QKV 机制、注意力计算和因果掩码来实现的。
1. QKV 机制 (Query, Key, Value)
每个输入向量(词+位置)都会被乘以三个独立的权重矩阵(Wq, Wk, Wv),从而派生出三个新的向量:
Q (Query)
“查询”:代表当前词在**寻找**什么信息。
K (Key)
“键”:代表当前词能**提供**什么信息。
V (Value)
“值”:代表当前词**真正包含**的全部信息。
Q = 输入向量 X Wq
K = 输入向量 X Wk
V = 输入向量 X Wv
2. 注意力计算与融合
模型通过以下步骤计算最终的上下文向量:
- 计算分数: 使用**点积 (Dot Product)** 计算当前词的 Q 向量与**所有**其他词的 K 向量的相似度分数。 Score = Q · K
- Softmax 归一化: 将分数转换为总和为 1 的概率分布(即注意力权重)。
- 加权融合: 使用这些权重对**所有**词的 V 向量进行加权求和,得到最终的输出向量。 Output = Σ (Attention Weight × V)
3. 因果自注意力 (Causal Self-Attention)
在**生成**任务中,模型在预测第 N 个词时,**绝不能**看到第 N+1 个词(“偷看未来”)。GPT 通过**注意力掩码 (Attention Mask)** 来实现这一点。
下图模拟了一个 4x4 的注意力分数矩阵(如处理 "我 爱 学 习")。在计算第 3 个词(“学”)的注意力时(第 3 行),它**只能**关注它自己和之前的词(第 1, 2, 3 列),而未来的词(第 4 列)被"掩码"(Masked)了。
绿色 = 允许关注 | 灰色 = 掩码 (未来词)
IV. 训练过程深度剖析
模型不是天生就“智能”的,它需要通过海量数据进行训练。GPT 的训练是一种“自监督学习”,核心任务是预测下一个词。
1. 学习任务:下一个词语预测
模型通过阅读海量非结构化文本(如书籍、网页),不断练习“填空”:给定前面的句子,预测紧接着的下一个词是什么。
2. 损失与评估
模型如何知道自己“猜”得对不对?通过**损失函数 (Loss Function)**。
- 核心机制: 交叉熵损失 (Cross-Entropy Loss) + 最大似然估计 (MLE)。
- 原理: 衡量模型预测的概率分布与“标准答案”(即文本中的真实词)之间的差距。
- 目标: 猜得越准,损失值越低。
3. 参数优化:梯度下降
模型的目标是找到让损失值最小的参数(权重矩阵)。这通过**梯度下降 (Gradient Descent)** 实现,可以想象成一个“盲人下山”的过程,不断朝着“最陡峭的下坡方向”(梯度的反方向)调整参数,直到找到山谷最低点(损失最小)。
最终,所有的“知识”和“规律”都存储在模型的**参数**中。
V. 推理与生成
训练完成后,模型就拥有了生成文本的能力。这个“推理”过程依赖强大的硬件和巧妙的生成策略来平衡准确性与创造性。
1. 硬件加速与效率
Transformer 的**并行处理**能力远超传统的 RNN。这使得它能完美利用现代硬件:
GPU (图形处理器)
拥有数千核心,擅长并行矩阵乘法。
TPU (张量处理器)
专为深度学习优化,矩阵运算效率更高。
2. 生成策略 (Sampling Strategies)
模型在预测下一个词时,会得到一个概率列表。如何从中选择一个词?
提示:"今天天气很好,我们去..."
点击按钮查看模拟输出...
Top-k 采样
只从概率最高的 k 个词中选择。例如 k=3,只在 "公园" (40%), "散步" (20%), "野餐" (15%) 中选。结果更可控、更稳健,适合事实问答。
Top-p 采样
选择概率累加和达到 p 的最小词集。例如 p=0.8,可能会选择 "公园" (40%), "散步" (20%), "野餐" (15%), "划船" (5%)。结果更灵活、更有创意,适合故事写作。